

A History of Machine Learning by Political Machines
I had the privilege of witnessing the growth in the use of analytics by the Democratic Party in the ‘90s and 2000s.

(source: ushmm.org) Eleanor Roosevelt: First Lady, diplomat, and symbol of world citizenship
Historically, the founder of machine learning for Democrats was Eleanor Roosevelt, the former First Lady and influential champion of universal human rights. Roosevelt founded the National Committee for an Effective Congress (NCEC) in 1948, which tracked vote totals by precinct and party throughout the country in every election. All of the data collected was used to turn out votes according to a simple algorithm:
- If precinct votes 66% or more for Democrats, try to get everybody to the polls.
- If precinct votes 33% – 66% for Democrats, canvas the precinct and only turn out the supporters.
- If precinct votes 33% or less for Democrats, ignore that precinct.
In other words, at the end of the 20th century, political machines used data to drive their decisions. That was the old kind of machine learning.
Starting in the 1990s, the research director for the NCEC, Ken Strasma, began using modern machine learning to model these precinct vote totals. His counterpart in the Republican Party was Karl Rove. On the Democratic side, the statistical models were used in an analogous manner to the NCEC precinct vote totals:
- If the model says the person is 66% or more likely to vote for the Democrat, get them to the polls.
- If the model says the person is 33% – 66% likely to vote for the Democrat, find out if they are supporting the Democrat.
- If the model says the person is 33% or less likely to vote for the Democrat, do not turn them out.
I did not know it at the time, but I saw something historic on Election Day 2000. At the final check-in from the bellwether precincts in Iowa, we (Team Gore) were headed for a narrow loss. A regional field director, Jon Carson, had insisted months earlier in putting voter ID numbers for Iowa online. Our national data director, Ryan Davies, quickly retrieved that file and appended phone numbers and Ken Strasma’s model outputs. Ryan set up last-minute, get-out-the-vote calls to 50,000 Iowa voters who were most likely to support Gore and least likely to vote. Those calls may have helped, as Gore won Iowa by 0.3%.
After that election, Laura Quinn moved mountains to raise the funds, assemble the team, and lead the overhaul of the Democratic Party’s web, data, and analytics infrastructure. The Republicans were able to conduct national targeting in 2000 because they had built a consolidated voter file covering all 50 states. As a key part of the overhaul, and with just a few years of effort, Lina Brunton miraculously consolidated the Democratic Party’s voter files, which had previously been controlled individually by the state parties. Between 2003 and 2008, the Democratic Party developed significant infrastructure on top of this standardized data substrate.
In 2008, the Democrats’ national field director, Jon Carson, insisted that the campaign volunteers be empowered and treated with respect. The volunteers were given access to the Party’s tools and data, and they were treated like staff. This visionary choice made Obama ‘08 the first internet-era campaign. Carson directed the volunteers to recruit other volunteers throughout the summer. This strategy yielded quadratic growth in our volunteer army and enabled more than one million get-out-the-vote calls every day in the last weekend of the campaign.
As the targeting and modeling lead for the Obama campaign, I was able to contribute to many first-time applications of analytics in political campaigning. Most significantly, at Jon Carson’s request, I developed a method of modeling persuadability for the undecided voters (i.e., voters modeled in the 33% – 66% range by our support models). These models enabled data managers in every state to pull lists, for example, of the 50,000 undecided voters who were most likely to be persuaded to vote for Obama.
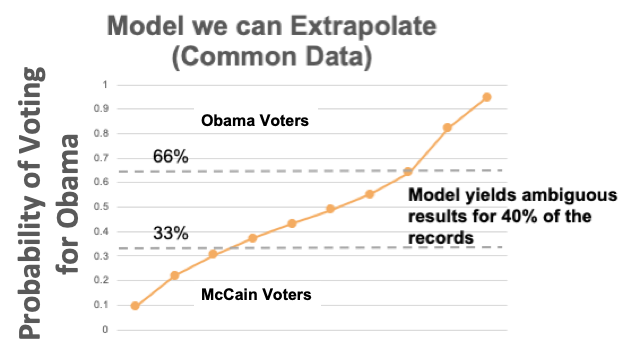
A typical voter support model shows the necessity of modeling voter persuadability. Models in this context are only useful if they form predictions from common data that are available for all voters. Surveys are used extensively in politics, but not for modeling support, because it is not feasible to survey all voters. Consequently, typical support models are ambiguous with respect to large portions of the electorate. In most battleground states, it is also not feasible to contact 40% of the voters (e.g., 2M+ voters in PA, 1.6M+ in MI, etc) and so the analytics team must prioritize these voters.
The 2008 campaign was both the beginning and the end of an era. Jon Carson had finally succeeded at bringing the open and collaborative culture of the early internet to political campaigning just as the culture of the internet was changing. His field campaign produced 17 million phone surveys before it was no longer reasonable to use landlines to reach a usefully broad sample of Americans. And finally, as various members of our campaign touted the contribution that analytics made, the era of machine learning and AI as a force in the industry began.
On election night in 2008, Ryan Davies, Ken Strasma, and I shared a toast from a bottle of cheap wine that Ryan had purchased in 2000 to celebrate our anticipated success. He had kept the bottle in his sock drawer throughout the intervening years. As truly horrible as that wine tasted, it went down like the bittersweet nectar of long-awaited victory.

Eric wrote the first Congressional website (by hand, in raw HTML!) and contributed to first websites at all levels of government. He was the chief software engineer for Gore 2000, chief internet architect for the Democratic National Committee, targeting and modeling lead for Obama ‘08, and a political appointee in the Department of Defense. Eric has a Ph.D. from MIT in cognitive neuroscience, an MS from UC Berkeley in adaptive signal processing, and a BS in mathematics from the University of Illinois.
-
How to Choose the Right LLM for Your Use Case
April 18, 2024· 7 min read -
Belong @ DataRobot: Celebrating 2024 Women’s History Month with DataRobot AI Legends
March 28, 2024· 6 min read -
Choosing the Right Vector Embedding Model for Your Generative AI Use Case
March 7, 2024· 8 min read
Latest posts
